GeneBench-Pro: an updated, verified benchmark for AI agents in biology
Evaluating long-horizon scientific reasoning in genomics, quantitative biology, and translational biomedicine
Views my own; nothing below is an official or unofficial view of OpenAI.
tl;dr Announcing GeneBench-Pro, an updated version of GeneBench including more difficult problems spanning a larger range of domains, with external verification by domain experts, shows continuing broad-based improvements in agentic biology capabilities. Also, some thoughts on benchmarks in biology.
Overview
A couple months ago, we released GeneBench (see preprint here), a benchmark focused on multi-stage problems in genomics and quantitative biology that was designed to fill the gap in the literature for realistic long-horizon scientific analyses in the life sciences.
Today we're announcing GeneBench-Pro, an expanded, updated, and more difficult benchmark evaluation suite covering a larger set of domains. GeneBench-Pro comprises 129 problems, of which 10 are open sourced, and of which 50 will be provided to Artificial Analysis for third-party benchmarking.
Links:
- OpenAI blog post
- Explore the 10 publicly released problems here
- HuggingFace link for the full 10 problems
- Preprint link
What's new
GeneBench-Pro expands the set of problems to cover a larger set of domains covering genomics, quantitative biology, and translational biomedicine, as shown in Figure 1. Compared to GeneBench, GeneBench-Pro adds 29 problems, drops 3, and significantly redesigns and hardens 54 of the remaining overlapping 100 problems. 82 of the 129 problems were also reviewed by third-party domain experts for scientific defensibility and fidelity in an effort to ensure that the problems are testing what we intend.
Performance of frontier models
The main model results are summarized in Figure 2.
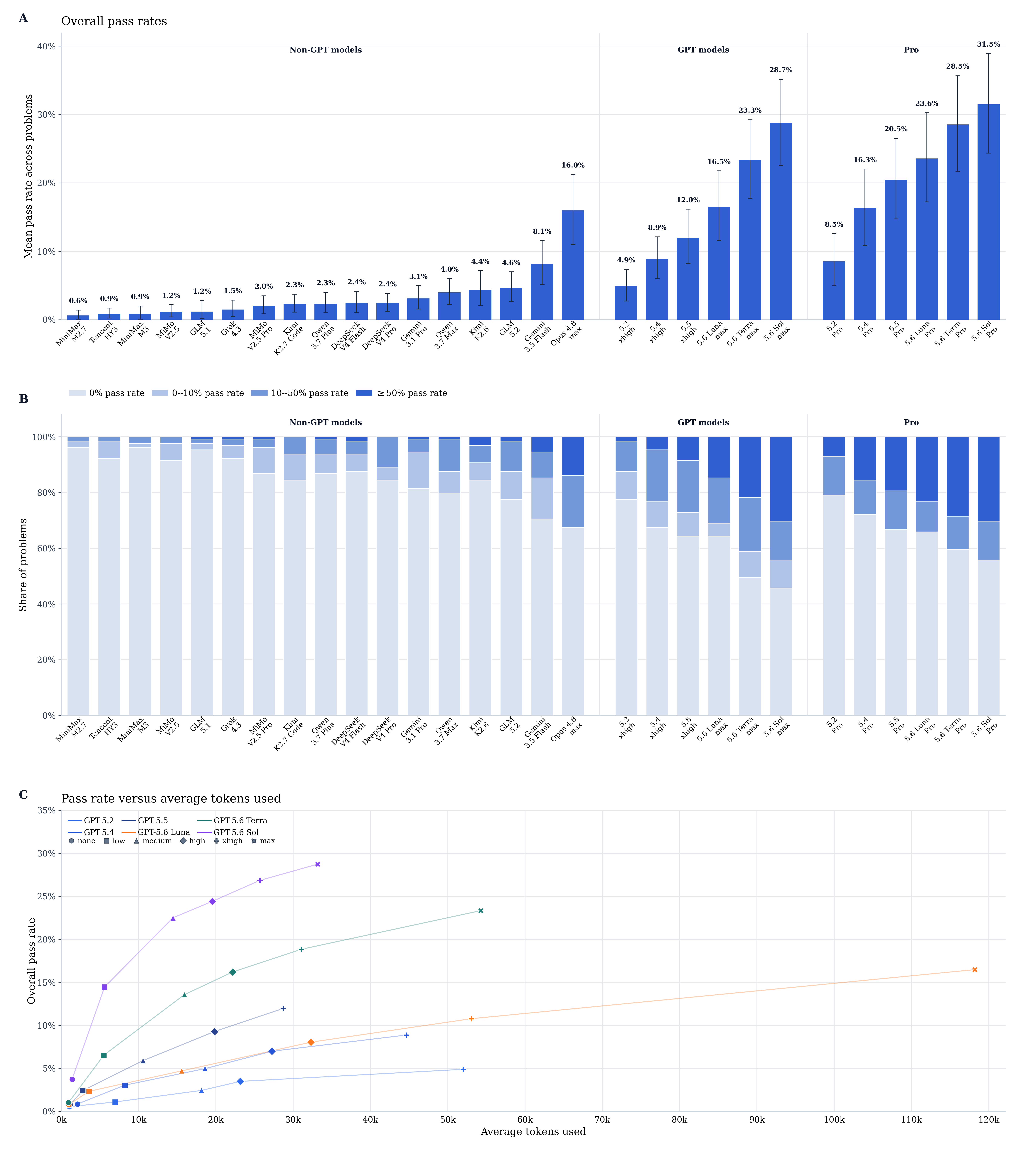
Compared to GeneBench, GeneBench-Pro is substantially more difficult, with the pass rate for GPT-5.5 at max reasoning effort dropping from 25% (GeneBench) to 12% for GeneBench-Pro. However, model progress proceeds apace, with GPT-5.6 Sol at max reasoning achieving a pass rate 28.7%. Non-GPT models in general score substantially worse, with the highest-scoring non-GPT model, Claude Opus 4.8, achieving a pass rate of 16.0%. More interestingly, the gap between GPT models and leading open source models such as GLM 5.2 is substantially larger for GeneBench-Pro than what one might expect according to coding benchmarks, illustrating that recent advances in model capabilities are not necessarily uniform across domains.
Qualitative analysis of GPT-5.6 Sol vs GPT-5.5 reasoning traces --- consistent with those of GPT 5.4 vs 5.5 as outlined in the original GeneBench post/preprint --- suggest that the improvements in performance are indeed due to more careful reasoning and better "scientific judgement"/"research taste".
These results are encouraging, yet the fact that the highest scoring models still are not yet able to answer a third of the total questions correctly is a reminder that current biological and statistical reasoning capabilities, even under purely synthetic conditions, have a ways to go before they can reliably and autonomously perform frontier life sciences research without supervision.
A few general thoughts on benchmarks in biology
Since GeneBench was released, there have been a number of newer benchmarks which have made some progress in helping to fill the benchmark gap in biology that we discussed in the original GeneBench post/preprint. Yet most of these existing benchmarks still do not convincingly show that they rigorously test the difficult-to-formalize skills that are the current bottleneck in measuring and hill-climbing agentic capabilities in the life sciences. Indeed, it is because that these skills are difficult to formalize that they are also difficult to assess rigorously, even as these skills increasingly become the constraining factor to overall model performance (as opposed to, for example, ability to execute a highly prescriptive workflow).
As we outline in our preprint,
Open-ended scientific analysis is difficult to benchmark precisely because real data often admit multiple defensible analysis choices... This is a particularly underappreciated issue in many existing long-horizon biology benchmarks, which are often based on real historical datasets around which new, multi-step questions are devised. In such data, extreme ambiguity is often present, to the extent that if one is, for example, taksed to apply a three-step QC or modeling pipeline to some real dataset, there is rarely necessarily exactly one correct path through this garden of forking paths --- at each of these three steps, there is a substantial probability that there exists an equally defensible choice that was not considered by the benchmark designer that ultimately leads to agents which make this choice to be graded as a failure, leading to a naturally decaying terminal pass rate with the length of the required inferential chain just by virtue of real-world messiness.
This sort of ambiguity has been empirically shown in "many analyst" experiments, wherein different expert teams given the same data and the same hypothesis often reach materially different answers. For example, in Silberzahn et al., 29 teams analyzed the same soccer dataset and estimated odds ratios ranging from 0.89 to 2.93 for the relationship between player skin tone and red-card decisions; 20 teams found a significant positive relationship, while 9 did not. In a larger social-science study, Breznau et al. coordinated 73 teams testing the same immigration-and-social-policy hypothesis and found estimates ranging from large negative to large positive effects, with more than 95% of the numerical-result variance left unexplained after coding identifiable workflow decisions. And in a more relevant domain, neuroimaging, Botvinik-Nezer et al. asked 70 teams to test the same 9 pre-specified fMRI hypotheses on the same dataset and found that no two teams chose identical workflows, with substantial variation in reported hypothesis-test results.
The lesson for benchmarking here is that if a problem is built around real data without fully specifying or controlling the data-generating process, there may be no single defensible terminal answer for an agent to recover, even when the analyst is competent and acting in good faith. Indeed, without first establishing that agents can actually perform the required statistical reasoning under controlled conditions, it is difficult to disentangle the component of agent performance on real-world-data benchmarks that can be attributed to model intelligence versus idiosyncrasies of the specific datasets that comprise the benchmark and of the benchmark designers.
Biological data is generated by slowly and noisily sampling from the real world, and such data represent the output of sampling in a way which makes it extremely difficult to comprehensively verify the implicit assumptions of benchmark designers. GeneBench-Pro therefore continues the GeneBench precedent of comprising purely synthetically generated problems where the full causal structure is known, and where we directly simulate the data-generating process.
Looking forward
Models are continuing to improve at an impressive clip, and as I discussed in the original GeneBench blog post, I think we are inching close to a future where scientific verification is the bottleneck for life sciences research, at least for in-silico/computational analyses (indeed I expect that data generation will remain the primary bottleneck to life sciences research in general for a longer time than most people assume, but this is a topic for a future blog post.).
Yet these results show that there is still a substantial way to go in evaluating and hill-climbing the skills that make experienced human researchers so valuable --- at the same time, that is what makes this such an exciting time to be in this field.
If you are interested in discussing how we might improve these capabilities, or just want to chat about more general applications of AI to life sciences research, feel free to drop me a line on X or shoot me an email at h.jeremy.li@gmail.com.